In this tutorial, we are going to vet some common pitfalls when using Redis.
Bitmaps are not always more memory-efficient than Sets
Consider the following example using the Set approach. Each user is represented by a Set. Each Set element is a deal to be sent. The deal IDs are sequential numbers(1,2,3,4…).
Create a file called benchmark-set.js in the tutorial6 folder with the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var redis = require("redis"); var client = redis.createClient(); var MAX_USERS = 10000; var MAX_DEALS = 6; var MAX_DEAL_ID = 1000; for(var i = 0; i < MAX_USERS; i++){ var multi = client.multi(); for(var j = 0; j < MAX_DEALS; j++){ multi.sadd("set:user:" + i, MAX_DEAL_ID - j, 1); } multi.exec(); } client.quit(); |
Flush your Redis database, execute the above code, and retrieve the used memory:
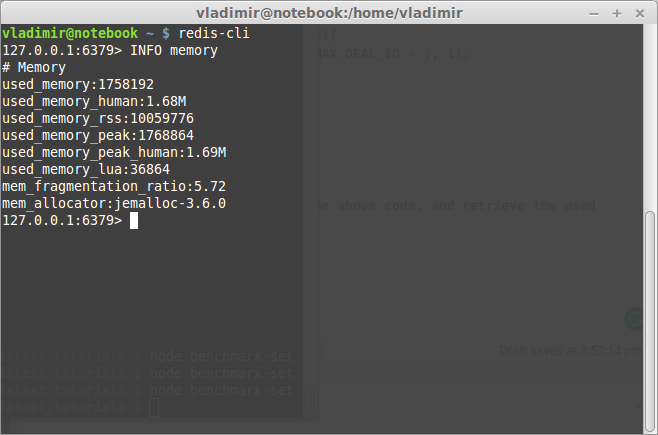
Now consider the bitmap approach. Each user is identified by a Bitmap. Each Bitmap has the deals marked as 1(they are going to be sent) or 0. If the highest deal is 20, the Bitmap is going to cost 21 bits.
Create a file called benchmark-bitmap.js in the tutorial6 folder with the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
var redis = require("redis"); var client = redis.createClient(); var MAX_USERS = 10000; var MAX_DEALS = 6; var MAX_DEAL_ID = 1000; for(var i = 0; i < MAX_USERS; i++){ var multi = client.multi(); for(var j = 0; j < MAX_DEALS; j++){ multi.setbit("bitmap:user:" + i, MAX_DEAL_ID - j, 1); } multi.exec(); } client.quit(); |
Now again, flush your Redis database, execute the above code, and retrieve the used memory:
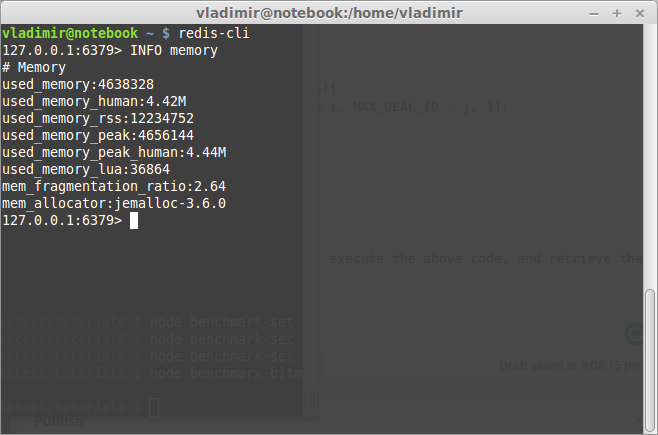
Notice, that the Bitmap approach uses 3 times more memory than the Set one.
Multiple databases
Redis has a support for multiple databases, which are represented by numbers. But this has become a deprecated feature because it is better to launch multiple Redis servers on the same machine. Redis is single threaded, so if multiple Redis servers are used, it is possible to take advantage of multiple CPU cores.
Use keys with namespace
It is good practice to use namespaces when defining keys in Redis. This helps to avoid key name collisions. In SQL databases, you may consider of a namespace as the database name or table.
Here are few examples of key names with namespaces:
– store:invoice:1
– store:invoice:2
– store:goods:10001:name
– store:goods:10001:price
– store:client:name
Swap
There is a Linux core parameter called swappiness. It controls when the OS starts using the swap space. It can be set from 0 to 100. A higher value tells the kernel to use the swap more frequently while a lower value is opposite. The default value is 60.
vm.swappiness=0 – disables swap entirely
vm.swappiness=1 – minimum amount if swapping
vm.swappiness=100 – Linux will swap aggressively
If you are sure that your data always fits in the RAM, then use 0, if not, then use 1.
To disable swap usage in Linux 3.5 and newer, you should modify the file /etc/sysctl.conf and add the following string:
vm.swappiness=0
Configure the memory properly
In the worst-case scenario, Redis server can double the used memory when performing the backup. During RDB snapshot, Redis server needs to duplicate itself(it uses the fork() system call). If the Redis instance is very busy during the fork() call, in this case, the child process may need the same amount of memory as his parent. During the fork() execution, the Redis server stops serving clients. This can be a bottleneck of your system.
To boost background saves, you should set the overcommit memory configuration to 1. Add the following line to the /etc/sysctl.conf file:
vm.overcommit_memory=1
There is also a configuration directive called maxmemory. It limits the amount of memory(in bytes) that Redis is allowed to use. Redis should not use more than 50% of the memory when any backup strategy is used.
That’s all for today 🙂
Вторичное уведомление. Добрый день! Вам начислена некоторая сумма, оформите вывод средств: http://tinyurl.com/Tewswege Получить возврат средств может каждый гражданин достигший совершеннолетия. SVWVE5285443TUJE
Вторичное уведомление. Добрый день! Вам начислена некоторая сумма, оформите вывод средств: http://tinyurl.com/Tewswege Получить возврат средств может каждый гражданин достигший совершеннолетия. JUYGTD1568266JUYGTD