In this tutorial, we are going to discover a few more data types like Set, Sorted Set, Bitmap, and HyperLogLog.
Sets
A Set is a collection of distinct strings. It is impossible to add repeated elements to a Set. A Set can hold more than 4 billion elements per Set.
You can use Sets for:
– data grouping. Something like recommended purchases in e-commerce sites.
– data filtering. Grouping all customers who bought the same product.
– checking for membership. Check whether the customer is in the patron group.
Commands:
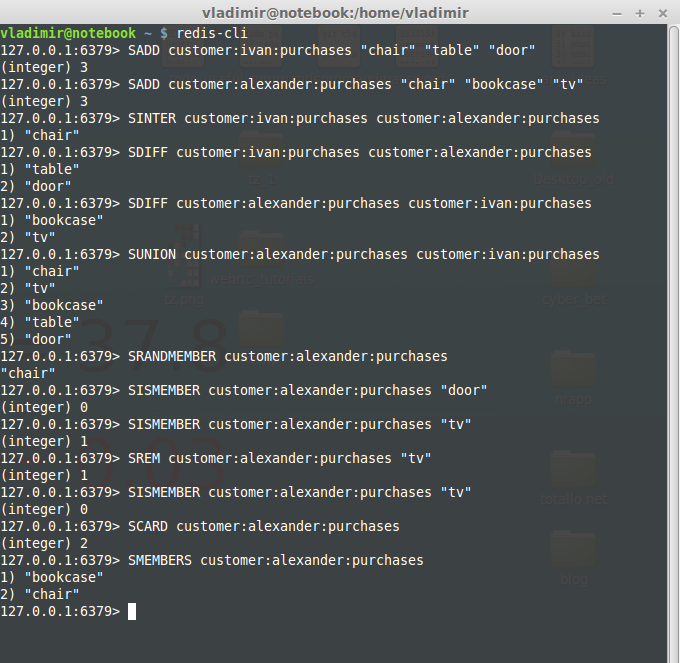
SADD: add one or many members to a Set. It ignores members that already exist in a Set and returns the number of added members.
SINTER: expects one or many Sets and returns an array of members that belong to every Set.
SDIFF: expects one or many Sets and returns an array of members of the first Set which do not exist in the following one.
SUNION: returns a union of Sets. All elements are unique.
SRANDMEMBER: returns a random member from a Set.
SISMEMBER: checks whether a member exists in a Set. Returns 1(exist) or 0(not exist).
SREM: removes and returns members from a Set.
SCARD: returns the number of members in a Set. (cardinality)
SMEMBERS: returns an array of all members in a Set.
Let’s create an example. Imagine we have an e-commerce site and we want to send our special Christmas offers to the users. We have to implement the following functions:
– mark offer as sent
– check whether a user received a group of offers
– gather metrics
Every offer is a Set containing user IDs that have received the offer. Create a file called christmas-offers.js with the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
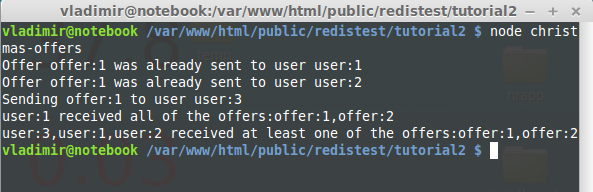
var redis = require("redis"); var client = redis.createClient(); //mark offer as sent to a particular user function markOfferAsSent(offerId, userId){ //execute the SADD command client.sadd(offerId, userId); } //checks whether a user ID belongs to a Set and send an offer if it was not sent function sendOfferIfNotSent(offerId, userId){ //the SISMEMBER function client.sismember(offerId, userId, function(err, reply){ //offer was sent if(reply){ console.log("Offer", offerId, "was already sent to user", userId); } else { //send an offer console.log("Sending", offerId, "to user", userId); //code to send an offer //... markOfferAsSent(offerId, userId); } }); } //show user IDs that exist in all Sets function showUsersThatReceivedAllOffers(offerIds){ //the SINTER command. Finding all users who received all offers client.sinter(offerIds, function(err, reply){ console.log(reply + " received all of the offers:" + offerIds); }); } //show user IDs that exist in any of the Sets function showUsersThatReceivedAtLeastOneOfTheOffers(offerIds){ //the SUNION command. Finding all users who received at least one offer client.sunion(offerIds, function(err, reply){ console.log(reply + " received at least one of the offers:" + offerIds); }); } markOfferAsSent('offer:1', 'user:1'); markOfferAsSent('offer:1', 'user:2'); markOfferAsSent('offer:2', 'user:1'); markOfferAsSent('offer:2', 'user:3'); sendOfferIfNotSent('offer:1', 'user:1'); sendOfferIfNotSent('offer:1', 'user:2'); sendOfferIfNotSent('offer:1', 'user:3'); showUsersThatReceivedAllOffers(["offer:1", "offer:2"]); showUsersThatReceivedAtLeastOneOfTheOffers(["offer:1", "offer:2"]); client.quit(); |
Now run the code via node christmas-offers. You should see the following console output:
Sorted Sets
A Sorted Set is a collection of nonrepeating Strings sorted by score. You can have elements with repeated scores. In this case, the repeated elements are ordered in alphabetical order. Sorted Set operations run in O(log(N)) time.
You can use Sorted Sets for:
– leaderboard for online games
– input autocomplete
– real time queue
Commands:
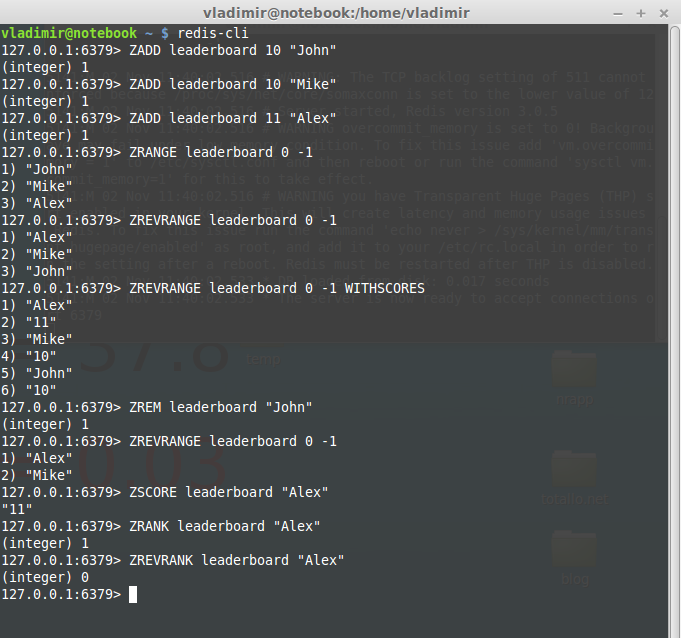
ZADD: adds one or many members to a Sorted Set. Returns the number of added members. Elements are added with a score and a String value.
ZRANGE: returns elements from the lowest to the highest score.
ZREVRANGE: returns elements from the highest to the lowest score. If you pass an optional parameter WITHSCORES it will return elements with their scores.
ZREM: removes a member from a Sorted Set
ZSCORE: returns the score of a member
ZRANK: returns the member index ordered from low to high. The member with the lowest score has index 0.
ZREVRANK: returns the member index ordered from high to low. The member with the highest score has index 0.
Let’s create an example. We will build a leaderboard for an online game. We have to implement the following functions:
– add and remove users
– display detailed user info
– show the top COUNT users
– show the users above and below a given user
Create a file leaderboard.js with the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
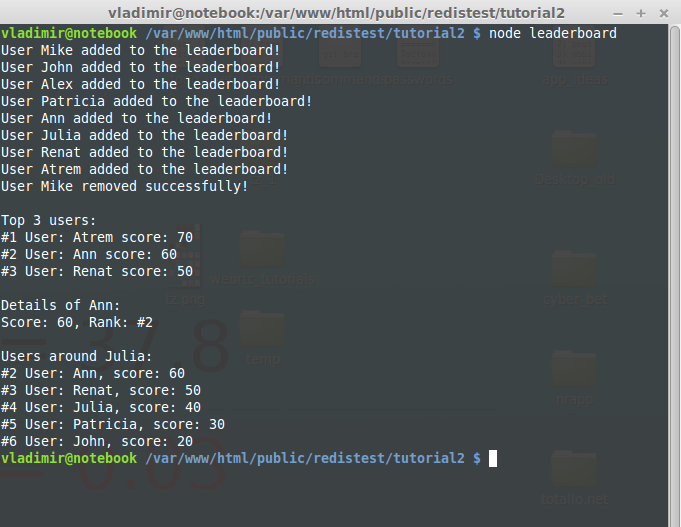
var redis = require("redis"); var client = redis.createClient(); //leaderboard constructor function LeaderBoard(key){ this.key = key; } //adding user to the leaderboard LeaderBoard.prototype.addUser = function(username, score){ //the ZADD command. Add user with a score to a Sorted Set client.zadd([this.key, score, username], function(err, replies){ console.log("User", username, "added to the leaderboard!"); }); }; //removing user LeaderBoard.prototype.removeUser = function(username){ //the ZREM command client.zrem([this.key, username], function(err, replies){ console.log("User", username, "removed successfully!"); }); }; //display user score and rank LeaderBoard.prototype.getUserScoreAndRank = function(username){ var leaderboardKey = this.key; //the ZSCORE command client.zscore(leaderboardKey, username, function(err, zscoreReply){ //the ZREVRANK command client.zrevrank(leaderboardKey, username, function(err, zrevrankReply){ console.log("\nDetails of " + username + ":"); console.log("Score:",zscoreReply + ", Rank: #" + (zrevrankReply + 1)); }); }); }; //returns QUANTITY users from highest to lowest score LeaderBoard.prototype.showTopUsers = function(quantity){ //the ZREVRANGE command client.zrevrange([this.key, 0, quantity - 1, "WITHSCORES"], function(err, reply){ console.log("\nTop", quantity, "users:"); //show username and score for(var i = 0, rank = 1; i < reply.length; i +=2, rank++){ console.log("#" + rank, "User: " + reply[i] + " score:", reply[i+1]); } }); }; //show users above and under the given user LeaderBoard.prototype.getUsersAroundUser = function(username, quantity, callback){ var leaderboardKey = this.key; //the ZREVRANK command. Get users from highest to lowest client.zrevrank(leaderboardKey, username, function(err, zrevrankReply){ //first element of the result var startOffset = Math.floor(zrevrankReply - quantity/2 + 1); if(startOffset < 0) startOffset = 0; //last element var endOffset = startOffset + quantity - 1; //get the list of users between startOffset and endOffset client.zrevrange([leaderboardKey, startOffset, endOffset, "WITHSCORES"], function(err, zrevrangeReply){ var users = []; for(var i = 0, rank = 1; i < zrevrangeReply.length; i += 2, rank++){ var user = { rank: startOffset + rank, score: zrevrangeReply[i+1], username: zrevrangeReply[i] }; users.push(user); } callback(users); }); }); }; var leaderBoard = new LeaderBoard("online-score"); leaderBoard.addUser("Mike", 80); leaderBoard.addUser("John", 20); leaderBoard.addUser("Alex", 10); leaderBoard.addUser("Patricia", 30); leaderBoard.addUser("Ann", 60); leaderBoard.addUser("Julia", 40); leaderBoard.addUser("Renat", 50); leaderBoard.addUser("Atrem", 70); leaderBoard.removeUser("Mike"); leaderBoard.getUserScoreAndRank("Ann"); leaderBoard.showTopUsers(3); leaderBoard.getUsersAroundUser("Julia", 5, function(users){ console.log("\nUsers around Julia:"); users.forEach(function(user){ console.log("#" + user.rank, "User:", user.username + ", score:", user.score); }); client.quit(); }) |
Now run the code via node leaderboard. You should see the following console output:
Bitmaps
A Bitmap is a sequence of bits. Each of them can store 0 or 1. Basically, Bitmap is an array of ones and zeroes.
See an example:
10011
This is a bitmap with one set on offsets 0,3,4 and zero set on offsets 1 and 2
Bitmaps are great for real-time analytics. For example, to make a report “How many users bought a product A yesterday?”.
The examples will show how to use Bitmap commands to userIDs of users who bought a given product. Each user is identified by an ID. Each Bitmap offset represents a user. For example, user 10 is offset 10, user 50 is offset 50, and so on.
Commands:
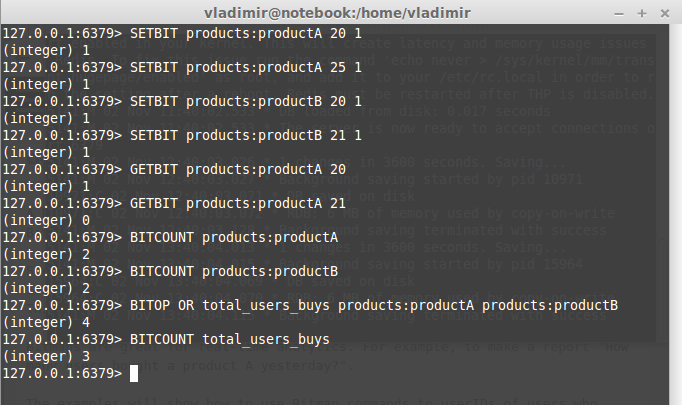
SETBIT: gives a value to a Bitmap offset.
GETBIT: returns a value of a Bitmap offset.
BITCOUNT: returns the number of bits marked as 1.
BITOP: requires a bitwise operation(OR, AND, XOR, NOT) and a list of keys to apply to this operation. It stores the result in the destination key.
The example application will be a web analytics system that saves and counts daily user visits and the retrieves userIDs from the visits on a given date.
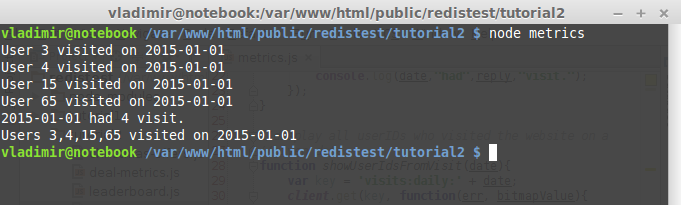
Create a file metrics.js with the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
var redis = require("redis"); //create a Redis client that uses Node.js buffers //instead of js strings var client = redis.createClient({return_buffers: true}); //store userID in a given date(YYYY-MM-DD) function storeDailyVisit(date, userId){ var key = 'visits:daily:' + date; //the SETBIT command. userId is an offset client.setbit(key, userId, 1, function(err, reply){ console.log("User", userId, "visited on", date); }); } //count the number of users who visited the website on a //given date function countVisits(date){ var key = "visits:daily:" + date; //the BITCOUNT command. Display the number of users //who visited the website in a given date client.bitcount(key, function(err, reply){ console.log(date,"had",reply,"visit."); }); } //display all userIDs who visited the website on a //given date function showUserIdsFromVisit(date){ var key = 'visits:daily:' + date; client.get(key, function(err, bitmapValue){ var userIds = []; var data = bitmapValue.toJSON(); //iterate over the bytes of the Bitmap data.forEach(function(byte, byteIndex){ //iterate over each bit of a byte for(var bitIndex = 7; bitIndex >= 0; bitIndex--){ //shift bytes to the right to remove the bits //that were already worked on var visited = byte >> bitIndex & 1; if(visited === 1){ var userId = byteIndex * 8 + (7 - bitIndex); userIds.push(userId); } } }); console.log("Users " + userIds + " visited on " + date); }); } storeDailyVisit('2015-01-01','3'); storeDailyVisit('2015-01-01','4'); storeDailyVisit('2015-01-01','15'); storeDailyVisit('2015-01-01','65'); countVisits('2015-01-01'); showUserIdsFromVisit('2015-01-01'); client.quit(); |
Now run node metrics. You should see the following console output:
HyperLogLogs
A HyperLogLog is not a real data type. It is an algorithm that uses randomization in order to provide a very good approximation of the number of unique members in a Set. It runs in O(1) constant time.
The HyperLogLog algorithm is probabilistic. It does not ensure 100 percent accuracy. The Redis implementation has an error of 0.81 percent. In some cases, 99.19 percent is good enough.
There are only three commands for HyperLogLogs: PFADD, PFCOUNT, PFMERGE. The prefix PF is in honor of Philippe Flajolet who is the author of the algorithm.
You can use HyperLogLogs for:
– counting the number of search terms on your website
– counting the number of unique users
– counting the number of distinct words on a page
– counting the number of distinct hashtags used by a user
Commands:
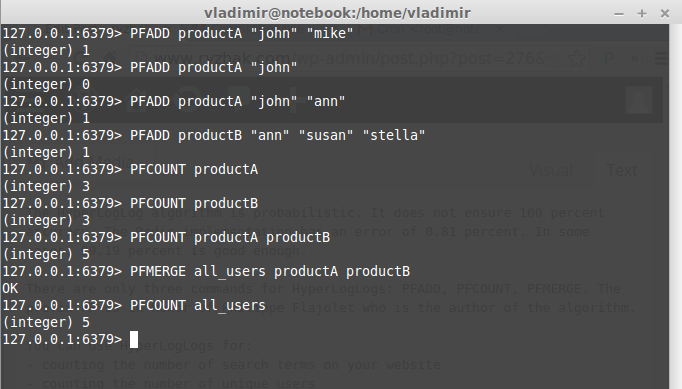
PFADD: adds one or many strings to a HyperLogLog. Returns 1(if the cardinality was changed) or 0(the cardinality remains the same).
PFCOUNT: accepts one or many keys as arguments. When there is a single argument, it returns the approximate cardinality. When there are multiple keys, it returns the approximate cardinality of the union of all unique elements.
PFMERGE: accepts a destination key and one or many HyperLogLog keys. It merges all the specified keys and stores the result in the destination key.
The example application will be a web system for counting and retrieving unique website visits. Each date will have 24 keys that represent each hour of a day.
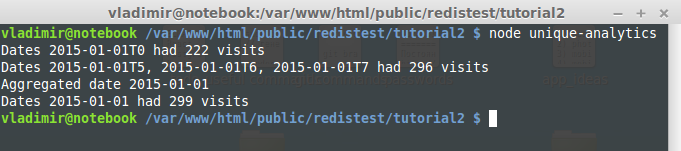
Create a file called unique-analytics.js and add the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
var redis = require("redis"); var client = redis.createClient(); //add a user visit for a specified date(YYYY-MM-DD or YYYY-MM-DDTH) function addVisit(date, user){ var key = 'visits:' + date; //the PFADD command client.pfadd(key, user); } //displays the count of unique visits in the given dates function count(dates){ var keys = []; //iterate over all dates dates.forEach(function(date, index){ keys.push('visits:' + date); }); //the PFCOUNT command client.pfcount(keys, function(err, reply){ console.log("Dates", dates.join(', '), "had", reply, "visits"); }); } //merge visits on a given date function aggregateDate(date){ var keys = ['visits:' + date]; //iterate over every hour of a day for(var i = 0; i < 24; i++){ keys.push('visits:' + date + 'T' + i); } //the PFMERGE command. Merge visits from all 24 hours into the destination key client.pfmerge(keys, function(err, reply){ console.log("Aggregated date", date); }); } var MAX_USERS = 300; var TOTAL_VISITS = 10000; //create random visits of random users on random hours for(var i = 0; i < TOTAL_VISITS; i++){ var username = 'user_' + Math.floor(1 + Math.random() * MAX_USERS); var hour = Math.floor(Math.random() * 24); addVisit('2015-01-01T' + hour, username); } count(['2015-01-01T0']); count(['2015-01-01T5', '2015-01-01T6', '2015-01-01T7']); aggregateDate('2015-01-01'); count(['2015-01-01']); client.quit(); |
Now run node unique-anaytics. You should see the following console output:
In this tutorial, we discovered Sets, Sorted Sets, Bitmaps, and HyperLogLogs. That’s all for today 🙂